<데이터타입 (DB)>
1. 숫자 NUMBER(X)
- 정수
- 실수
2. 문자 ( ' ' 사용)
- 고정형 CHAR(X) -> X는 length를 의미, 체인화가 발생하지 않음.
- 가변형 VARCHAR2(X) -> X는 length를 의미, 체인화가 발생하므로 튜닝 필요.
3. 날짜 DATE(XX/XX/XX) -> 23/10/26 - 슬래시 사용, 8byte )
- 데이터타입으로 DB에만 있는 것.
- 날짜로 통계내는 경우가 많기 때문에 DB에서 날짜가 꽤 중요함.
- 연산 가능 ( /로 표현하지 않으면 날짜로 인식을 못하기 때문에 꼭 / 사용)
4. 대용량 문자열 (CLOB타입)
5. 멀티미디어 (사진, 음악) (BLOB타입) -> 직접 테이블에 넣기에는 용량이 커서 보통 문자타입으로 주소를 넣어준다.
특이점 : DB는 메모리가 하니라 실제 하드디스크에 파일로 저장되어 공간을 차지함.
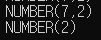
// NUMBER(7,2) -> XXXXXXX.XX (length)
// NUMBER(2) -> XX (length)
DB는 개발자가 어떻게 구현하는지에 따라 성능이 달라진다.
가장 적은 시간에 블럭에 접근해서 잡아오는 것이 DB의 최종 목적.
그래서 DB에서는 튜닝이 중요하다.
DB에서 인덱스가 정말 중요하다. 데이터를 쉽게 찾게 하기위해서. (-> where절)
----------------------------------------------------------------
식별자 = 사용자정의 (내 맘대로 만들어 쓰는 것)
----------------------------------------------------------------
<연산자 정렬 (DB)>
select 데이터추출
select 컬럼명, ... from 테이블명, ... -- 제한된 컬럼을 추출 (컬럼밖에 제한 못함, 행은 데이터라 건들 수 없음.)
select * from emp; -- 모든 컬럼을 볼 때
where -- 제한된 데이터(행)을 추출함. where절에 참(true)인 행이 대상이다.
show all --현재 세션의 환경들을 보여줘
set --내가 원하는 환경으로 바꾸기
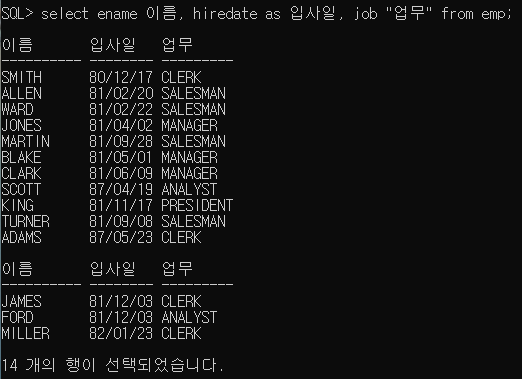
select ename 이름, hiredate as 입사일, job "업무" from emp; -- 별칭 바꾸는 방법 3가지 (" "이걸 가장 많이 씀, as는 생략가능)
<연산자>
1. 산술연산자 : + , - , *, / , mod(10,3)=1
2. 관계연산자 : = , !=(<>) , > , < , >= , <=
* null은 비교/연산이 안되기 때문에 is 또는 is not 으로 참 거짓을 판단해야 함.
* null 대체함수 : nvl(컬럼, 대체값) -> 컬럼 하나에 단독 적용됨.
3. 문자열연산자 : like
---------
4. 논리연산자 : not > and > or
-- in연산자가 or랑 같다고 보면 됨.
job in('SALESMAN','CLERK'); = IN(A, B, ...) (A or B or ...)
<변환>
to_char
to_date('23/10/26 18:00:00', 'yy/mm/dd hh24:mi:ss');
----------------------------------------------------------------
<정렬>
가급적 정렬작업 하지 말 것. 메모리를 잡아먹음.
select 명령에서 가장 마지막에 위치하며 연산작업은 없다.
영문보다 한글이 더 큰값.
null은 큰 값으로 처리. 따라서 0으로 바꿔주던가 해야함.
형식
order by 컬럼명 (별칭 | 순서번호) (asc) | desc, ....
오름차순은 1 → 2 → 3 → 4 → …… 와 같이 뒤로 갈수록 숫자가 커지는 경우이고 내림차순은 그 반대
----------------------------------------------------------------
// 연습문제
1. 부서번호가 20번인 부서의 사원들을 추출
select ename, deptno from emp
where deptno=20;
2. 급여가 1000~2000인 사람들을 추출
select ename, sal from emp
where sal>=1000 and sal<=2000; (이걸 더 선호함)
또는
select ename, sal from emp
where sal between 1000 and 2000; (=between A and B) (A~B) 잘 사용하지 않음. 이상 이하만 계산하고, 초과 미만을 계산을 못하기 때문.)
3. 커미션이 null인 사람들을 추출
select ename, comm from emp
where comm is null; (null은 비교연산이 안되기 때문에 =를 사용할 수 없음)
4. 급여가 1000~2000이 아닌 사람들을 추출
select ename, sal from emp
where sal<1000 or sal>2000;
5. job이 salesman, clerk인 사람을 추출
select ename, job from emp
where job='SALESMAN' or job='CLERK';
또는
select ename, job from emp
where lower(job)='salesman' or lower(job)='clerk'; // 값의 대/소문자를 구분(upper대문자로바꾸거나 or lower소문자로바꾸거나)
6. comm과 sal+comm의 null값을 0으로 변경하여라.
select nvl(comm, 0) "comm", sal+nvl(comm, 0) "총급여" from emp;
(null 대체함수 : nvl(컬럼, 대체값) -> 컬럼 하나에 단독 적용됨.)

SQL> select 125*560 from dual;
125*560
----------
70000
SQL> select sysdate from dual;
SYSDATE
--------
23/10/26
SQL> select to_char (sysdate, 'yy/mm/dd hh24:mi:ss') from dual;
TO_CHAR(SYSDATE,'
-----------------
23/10/26 15:17:38
7. insert into emp(empno, ename, hiredate) values(101, '홍동우', sysdate); 일 때
입사일이 '87/01/01~'23/10/26;인 사람을 추출(날짜 제한)
select ename, hiredate from emp
where hiredate>='87/01/01' and hiredate<'23/10/27';
8. insert into emp(empno, ename, hiredate) values(101, '홍동우', sysdate); 일 때
입사일이 '23/10/26'자정~오후6시까지인 사람을 추출(시간 제한)
select ename, hiredate from emp
where hiredate>='23/10/26' and hiredate<=to_date('23/10/26 18:00:00', 'yy/mm/dd hh24:mi:ss');
9. [xxx의 급여는 xxx이다] 형태로 추출 (|| : 연결 연산자)
select ename || '의 급여는 ' || sal || '이다' as 정보 from emp;
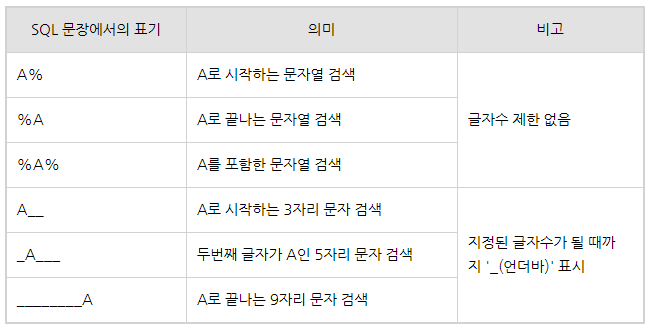
10. 이름이 A로 시작하는 사람을 추출
select ename from emp
where ename like 'A%';
11. 이름에 L을 포함하는 사람을 추출
select ename from emp
where ename like '%L%';
12. 이름의 두번째 문자가 L인 사람을 추출
select ename from emp
where ename like '_L%';
13. 이름에 L을 두번 이상 포함하는 사람을 추출
select ename from emp
where ename like '%L%L%';
14. 부서별로 정렬하되, (아무말 없으면 오름차순 하라는 것. asc)
같은 부서 사람들은 급여가 높은 순서대로 정렬하여 추출
select deptno, ename, sal from emp
order by deptno, sal desc;
또는
select deptno, ename, sal from emp
order by 1, 3 desc;
15. 부서별로 정렬하되, (아무말 없으면 오름차순 하라는 것. asc)
같은 부서 사람들은 급여가 높은 순서대로 정렬하여 추출
단, 급여가 없는 홍동우 사원은 제외하라
select deptno, ename, sal from emp
where sal is not null
order by 1, 3 desc;
-----------------------------------------------------
<선생님이 정리해주신>
<연산자 정렬>
-- 데이터 추출
select 컬럼명 (as) "별칭",... from 테이블명,...; // 제한된 컬럼***을 추출
*** 연산자
--where절 : 제한된 데이터(행)***를 추출 => where절에 참인 행이 대상
1. 산술 연산자 : +, -, *, /, mod(10,3)=1
2. 관계 연산자 : =, !=(<>), >, <, >=, <=
3. 문자열 연산자 : like(%-모든문자, _-한 문자)
----------
4. 논리 연산자 : not > and > or
--부서번호가 20번인 부서의 사원들을 추출
select deptno, ename from emp
where deptno=20;
-- 급여가 1000~2000인 사람을 추출
select ename, sal from emp
where sal >= 1000 and sal <= 2000;
-- sal between 1000 and 2000; // between A and B : A~B
-- sal < 1000 or sal > 2000; // 1000~2000은 제외
* null은 비교/연산 안됨
-- 커미션이 null인 사람을 추출
select ename, comm from emp
where comm is null;
-- 널 대체함수 : nvl(컬럼, 대체값)
select ename, sal, nvl(comm, 0) "COMM", sal+nvl(comm,0) "총급여" from emp;
-- 업무(job)가 salesman, clerk인 사람을 추출
select ename, job from emp
where lower(job)='salesman' or lower(job)='clerk'; // 값의 대/소문자를 구분*(upper & lower)
-- job in('SALESMAN','CLERK'); // in(A, B,...) : A or B or ....
insert into emp(empno, ename, hiredate) values(101, '홍동우', sysdate);
SQL> select sysdate from dual;
SYSDATE
--------
23/10/26
SQL> select to_char(sysdate, 'yy/mm/dd hh24:mi:ss') from dual;
TO_CHAR(SYSDATE,'
-----------------
23/10/26 15:16:41
-- 입사일이 '87/01/01'~'23/10/26'인 사람을 추출(A~B 날짜 제한)
select ename, hiredate from emp
where hiredate>='87/01/01' and hiredate<'23/10/27'; //***
--입사일이 '23/10/26' 자정~오후 6시까지인 사람을 추출(시간** 제한)
select ename, hiredate from emp
where hiredate>='23/10/26' and hiredate<= to_date('23/10/26 18:00:00', 'yy/mm/dd hh24:mi:ss');
--[xxx의 급여는 xxx이다] 형태로 추출(|| : 연결 연산자)
select ename || '의 급여는 ' || sal || '이다' as 정보 from emp;
--이름이 A로 시작하는 사람을 추출
select ename from emp
where ename like 'A%';
-- 이름에 L을 포함하는 사람을 추출
select ename from emp
where ename like '%L%';
-- 이름의 두번째 문자가 L인 사람을 추출
select ename from emp
where ename like '_L%';
-- 이름에 L을 두번 이상 포함하는 사람을 추출
select ename from emp
where ename like '%L%L%'
*** 정렬작업
-- 가급적 정렬작업 회피
-- select 명령에서 가장 마지막에 위치하며, 연산작업은 없다
-- 영문 < 한글, null은 큰값으로 처리
--형식
order by 컬럼명(별칭|순서번호) (asc) | desc,...
-- 부서별로 정렬하되, (같은 부서사람들은) 급여가 높은 순서대로 정렬하여 추출
-- 단, 급여가 널인 사람을 제외
select deptno, ename, sal from emp
where sal is not null
order by 1, 3 desc;
-----------------------------------------------------
// 오늘 숙제
1. emp table의 모든 열을 하나의 열로 출력하라.
(단, 각 열은 쉼표로 구분하며 표시하고, 열의 이름은 THE_OUTPUT으로 지정하라)
select empno || ',' || ename || ',' || job || ',' || mgr || ',' || hiredate || ',' || sal || ',' || comm || ',' || deptno || ' 'as THE_OUTPUT from emp;
2. 급여가 1500 ~ 2850 사이의 범위에 속하지 않는 모든 사원의 이름 및 급여를 표시하라.
select ename, sal from emp
where sal<1500 or sal>2850;
3. 1981년 2월 20일 ~ 1981년 5월 1일에 입사한 사원의 이름, 직위 및 입사일을 표시하라.
(입사일을 기준으로 오름차순 정렬할 것!)
select ename, job, hiredate from emp
where hiredate>='81/02/20' and hiredate<'81/05/02';
order by hiredate;
4. 부서가 10, 30에 속하는 사원 중 급여가 1500을 넘는 사원의 이름 및 급여를 표시하라.
select deptno, ename, sal from emp
where deptno in(10, 30) and sal>1500;
5. 1982년에 입사한 모든 사원의 이름과 입사일을 표시하라.
select ename, hiredate from emp
where hiredate>='82/01/01' and hiredate<'83/01/01';
6. 이름에 L이 두 번 들어가며 부서 30에 속하거나 관리자 번호가 7782인 모든 사원의 이름을 표시하라.
select deptno, ename, mgr from emp
where ename like '%L%L%' and deptno=30 or mgr=7782;
7. 직위가 CLERK, ANALYST 이면서 급여가 1000, 3000, 5000가 아닌 모든 사원의 이름, 직위 및 급여를 표시하라.
select ename, job, sal from emp
where job in ('CLERK','ANALYST') and sal not in (1000,3000,5000);
8. 사원번호, 이름, 급여 및 15% 인상된 급여를 함께 추출하고 열 레이블(별칭)을 NEW SALARY로 하라.
select empno, ename, sal, sal*1.15 as "NEW SALARY" from emp;
9. 8번 문제에 인상분만을 표시하는 열을 추가하여 추출하고, 열 이름을 INCREASE 로 하라.
select empno, ename, sal, sal*1.15 as "NEW SALARY", sal*0.15 as "INCREASE" from emp;
10. 사원 이름 및 커미션을 표시하는 질의를 작성한다.
커미션을 받지 않는 사원일 경우 ‘No Commision’을 표시하고 열 이름을 COMM으로 지정한다.
select ename, nvl(to_char(comm), 'No Commission') "COMM" from emp;
11. 이름에 L이 두번만 포함하는 사람을 추출-instr함수
select ename from emp
where instr(ename, 'L', 1, 2)>0 and instr(ename, 'L', 1, 3)=0; --instr(문자열,찾을문자,검색시작위치,N번째)
-- 이름에 L이 두 번 포함되었지만 세 번 이상 포함되지 않은 행을 선택
----------------------------------
<선생님이 정리해주신>
1. 연산자_과제&답안
<EMP> Table
1. emp table의 모든 열을 하나의 열로 출력하라.
(단, 각 열은 쉼표로 구분하며 표시하고, 열의 이름은 THE_OUTPUT으로 지정하라)
SQL> select empno||','||ename||','||job||','||mgr||','||hiredate||','||sal||','||comm||','||deptno
as THE_OUTPUT from emp;
2. 급여가 1500 ~ 2850 사이의 범위에 속하지 않는 모든 사원의 이름 및 급여를 표시하라.
SQL> select ename, sal from emp where sal<1500 or sal>2850;
3. 1981년 2월 20일 ~ 1981년 5월 1일에 입사한 사원의 이름, 직위 및 입사일을 표시하라.
(입사일을 기준으로 오름차순 정렬할 것!)
SQL> select ename, mgr, hiredate from emp where hiredate>='81/02/20' and hiredate<'81/05/02';
4. 부서가 10, 30에 속하는 사원 중 급여가 1500을 넘는 사원의 이름 및 급여를 표시하라.
SQL> select ename, sal from emp where (deptno=10 or deptno=30) and sal>=1500;
5. 1982년에 입사한 모든 사원의 이름과 입사일을 표시하라.
SQL> select ename, hiredate from emp where hiredate>='82/01/01' and
hiredate<='83/01/01';
6. 이름에 L이 두 번 들어가며 부서 30에 속하거나 관리자 번호가 7782인 모든 사원의 이름을 표시하라.
SQL> select ename from emp where ename like '%L%L%' and (deptno=30 or
empno=7782);
7. 직위가 CLREK, ANALYST 이면서 급여가 1000, 3000, 5000가 아닌 모든 사원의 이름, 직위 및 급여를 표시하라.
SQL> select ename, job, sal from emp
where (job='CLERK' or job='ANALYST') and (sal !=1000 or sal !=3000 or sal !=5000);
8. 사원 번호, 이름, 급여 및 15% 인상된 급여를 함께 추출하고 열 레이블(별칭)을 NEW SALARY로 하라.
SQL> select deptno, ename, sal, sal*1.15 "NEW SALARY" from emp;
9. 8번 문제에 인상분만을 표시하는 열을 추가하여 추출하고, 열 이름을 INCREASE 로 하라.
SQL> select empno, ename, sal, sal*1.15 as "NEW SALARY", sal*0.15 as "INCREASE" from emp;
10. 사원 이름 및 커미션을 표시하는 질의를 작성한다.
커미션을 받지 않는 사원일 경우 ‘No Commision’을 표시하고 열 이름을 COMM으로 지정한다
SQL> select ename, nvl(to_char(comm),'No Commision') comm from emp;
11. 이름에 L이 두번만 포함하는 사람을 추출-instr함수
SQL> select ename from emp
where instr(ename, 'L', 1, 2)>0 and instr(ename, 'L', 1, 3)=0; --instr(문자열,찾을문자,시작위치,N번째)
'DataBase' 카테고리의 다른 글
| <DataBase_231101수> 다중행 함수 (0) | 2023.11.01 |
|---|---|
| <DataBase_231031화> 단일행 함수 문제&답안 (2) | 2023.10.31 |
| <DataBase_231030월> 단일행 함수 (0) | 2023.10.30 |
| <DataBase_231027금> 테이블, DDL 제약조건 (2) | 2023.10.27 |
| <DataBase_231025수> SQL plus 명령 (2) | 2023.10.25 |